
As large language models (LLMs) find their way into real-world applications—such as chatbots, code assistants, customer service, and research tools—understanding how they behave in the wild has become just as important as building them. That’s where LLM observability steps in.

Unlike traditional software, LLMs are dynamic and unpredictable. A single prompt can return multiple variations. Even small changes in input can yield unexpected responses. This non-determinism, combined with the scale of use, makes real-time monitoring, auditing, and analysis essential, not optional.
What Is LLM Observability?
LLM observability refers to the practice of continuously tracking and analysing the performance, reliability, and behaviour of a deployed large language model in production environments.
It’s about answering key questions:
- Is the model generating accurate, safe, and useful outputs?
- Are there patterns of bias, hallucination, or inconsistency?
- Is the latency acceptable for real-time use cases?
- Are certain prompts resulting in problematic or off-brand responses?
Just like observability in traditional software tracks logs, metrics, and traces, LLM observability tracks prompts, completions, latency, token usage, user feedback, and safety issues.
Why LLM Observability Matters
1. LLMs Are Non-Deterministic
You can’t write a test for every possible output. What you need instead is visibility into what the model is doing in production, how users are interacting with it, and what it’s returning.
2. Output Quality Can Vary Wildly
Generative models might produce brilliant answers or confidently generate something factually wrong. Observability helps catch these inconsistencies and provide data for continuous fine-tuning.
3. Bias & Safety Risks Are Real
Without monitoring, you might not notice when a model returns biased, offensive, or inappropriate responses. LLM observability flags these early and helps retrain models or adjust safety layers.
4. Cost Can Get Out of Control
Token usage per response matters, especially with pay-per-token APIs like OpenAI or Anthropic. Observability gives insight into which types of queries consume more resources and helps optimize usage.
5. User Experience Is Everything
Latency, time-to-response, and output relevance directly affect UX. With observability, teams can track slowdowns, pinpoint what’s causing them, and act fast.
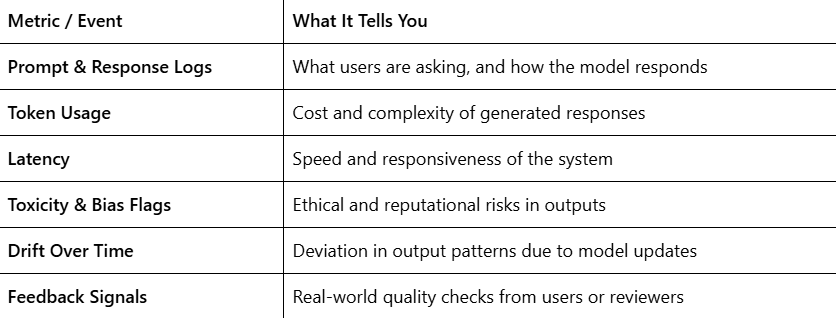
What to Monitor in an LLM System
Real-World Example
Let’s say a banking chatbot powered by an LLM begins misinterpreting loan-related queries. Without observability, this could go unnoticed until customers complain. But with LLM observability in place, the system logs a spike in irrelevant or confusing responses, flags them for review, and allows teams to adjust prompt templates or apply a safety filter before users are frustrated.
Building an Observability-First LLM Workflow
- Log Everything (Securely) – Capture prompt-response pairs with user context, while respecting privacy.
- Label and Score Output Quality – Use manual reviews, automated metrics (like perplexity or BLEU), or user ratings to assess usefulness and relevance.
- Track Bias and Harm Indicators – Integrate bias detection tools or flag outputs that exceed toxicity thresholds.
- Detect Drift or Unexpected Changes – Set up alerting for major shifts in response patterns post-deployment or after fine-tuning.
- Enable Human Feedback Loops – Let users flag responses, rate usefulness, or annotate errors. This is gold for iterative improvement.
Why It’s Not Just for Data Scientists
LLM observability isn’t just an MLOps function. Product teams, legal, customer support, and even marketing benefit from knowing what the model is saying, how it aligns with brand tone, and whether it’s delivering value to users.
From Experimentation to Maturity
LLMs are no longer side projects. They’re embedded into workflows, user interfaces, and decisions. As their footprint grows, so does the need for structured observability that moves beyond passive logging to active, actionable insights. As LLMs power more critical business applications, observability is the foundation for reliability, safety, and continuous improvement.
It’s how teams move from “hope it works” to “we know how it’s working.” You can’t fix what you can’t see—and with LLMs, visibility is everything.
Want to explore more about GenAI observability and real-world AI monitoring?
Check out our related blog: GenAI Observability Trends in 2025